[note: this is an activity I developed for my Smith College “Doing Digital History” class from Spring 2020]
This quick guide is based on a more complete tutorial in The Programming Historian.
Step 1: Download these three things
Download the SOTU corpus. [this is a slightly modified version of a corpus I found here]
- N.B.: the Java kit takes about 300mb of space. If you’d prefer not to install software on your personal computer, hop onto one of the classroom PCs.
- I have written these instructions for Mac users, but they can be easily translated to PC instructions. Using PC guidelines mostly involves making sure that the slashes go the opposite way. See Mac and PC directions on The Programming Historian site.
Step 2: Install MALLET
- Unzip the MALLET file.
- Place it in the /user/ directory.
- Place the “sotu” file, without changing any names, within the MALLET file directory.
Step 3: Open Terminal and begin entering some commands
In the command line, enter:
cd mallet-2.0.8
This will tell the Terminal to change change the directory to MALLET. If you get an error message, that probably means that the MALLET file isn’t in your Users directory.
Next, enter this code at the command line:
./bin/mallet import-dir --input sotu --output sotu.mallet --keep-sequence --remove-stopwords
For PCs, enter this command:
bin\mallet import-dir --input sotu --output sotu.mallet --keep-sequence --remove-stopwords
This command tells MALLET to take the corpus within the “sotu” file, and transform it into a single, readable file. It will also remove common “stopwords,” like “and” or “the,” which aren’t helpful for textual analysis. It should return with:
"Labels =
sotu"
Next, enter this command:
bin/mallet train-topics --input sotu.mallet --num-topics 20 --optimize-interval 20 --output-state sotu.gz --output-topic-keys sotu_keys.txt --output-doc-topics sotu_composition.txt
For PCs, the command is:
bin\mallet train-topics --input sotu.mallet --num-topics 20 --optimize-interval 20 --output-state sotu.gz --output-topic-keys sotu_keys.txt --output-doc-topics sotu_composition.txt
This is more complicated. It tells MALLET to take the file that it just created and to analyze it for 20 topics (“–nom-topics 20”). Depending on the speed of your machine, it may take around a minute to process.
Step 4: Analyze the Keys
It will spit out two files that you need to look at. First, the “keys” will look something like this, but different:
 (Click for larger view)
(Click for larger view)In the mallet folder, which should still be in your “user” file, you will find a document called sotu_keys.txt. Open it up.
If something prevented you from running the topic model, here are my sample keys and composition.
Each line, numbered 0 through 19 on the left, represents a “topic.” The decimal number next to the words represents the prevalence of that particular topic throughout the corpus. The string of 20 disconnected words are some of the words that MALLET identified as being part of a topic. MALLET doesn’t have the ability to tell you what each topic is about. You need to figure that out for yourself.
Some of the topics may be difficult to discern. But others might be intriguing. Consider topic 16, above:
war free nations world military peace production forces united communist men defense effort strength aggression fighting soviet attack europe peoples
Given that we know that these topics come from States of the Union, we can probably guess that the topic that’s identified here has something to do with war, particularly in the 20th century given that we see words like “communist” and “soviet.” To test that hypothesis, we need to look at the “composition” file.
Step 5: Composition
Open your second file, “sotu_composition.txt” in Microsoft Excel (if possible). This will make it easier to analyze. But it’s still a bit bewildering, so we’ll have to organize it a bit. In order to do that, add a new top row, and do a “find and replace” and get rid of the extraneous material in column B (everything other than the year and .txt). Sort the file by column B, so that the rows are ordered by year. You can add the name of each topic to the first row.
Your file should look something like this:
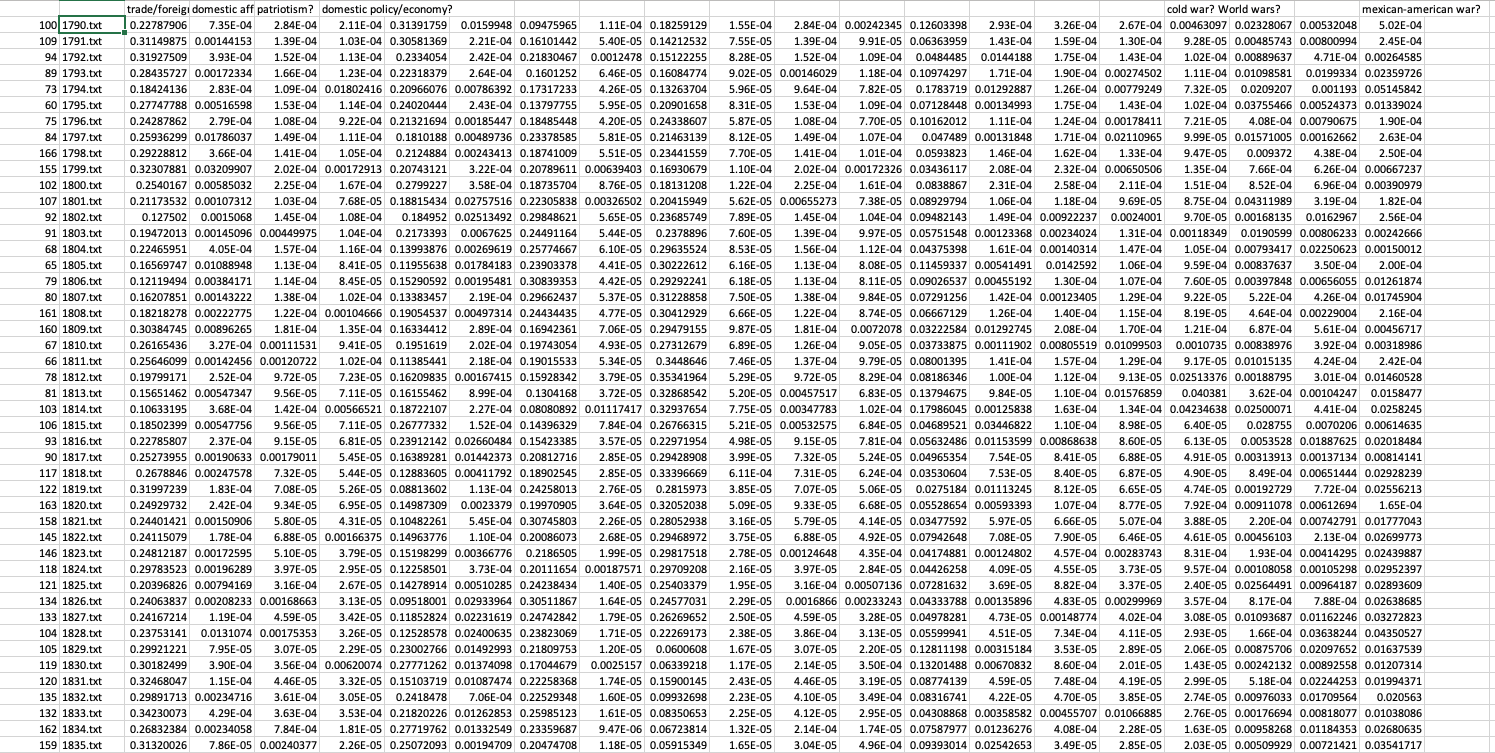 (Click for a larger view)
(Click for a larger view)Each row represents a text file, or a State of the Union. Each column represents a topic that MALLET has identified.
Now you can graph the topics. In this example, I’ll try topic 16, which we looked at earlier, which is in column S. By graphing column S, you can see the relative frequency of that topic across the corpus. Because we’ve ordered the corpus by year, and because there’s one SOTU every year (with very few exceptions) you get a year-by-year breakdown of when each topic appeared.
Once I’ve selected column S, inserted a line graph of it, and added horizontal labels to it, I get a graph that looks like this:
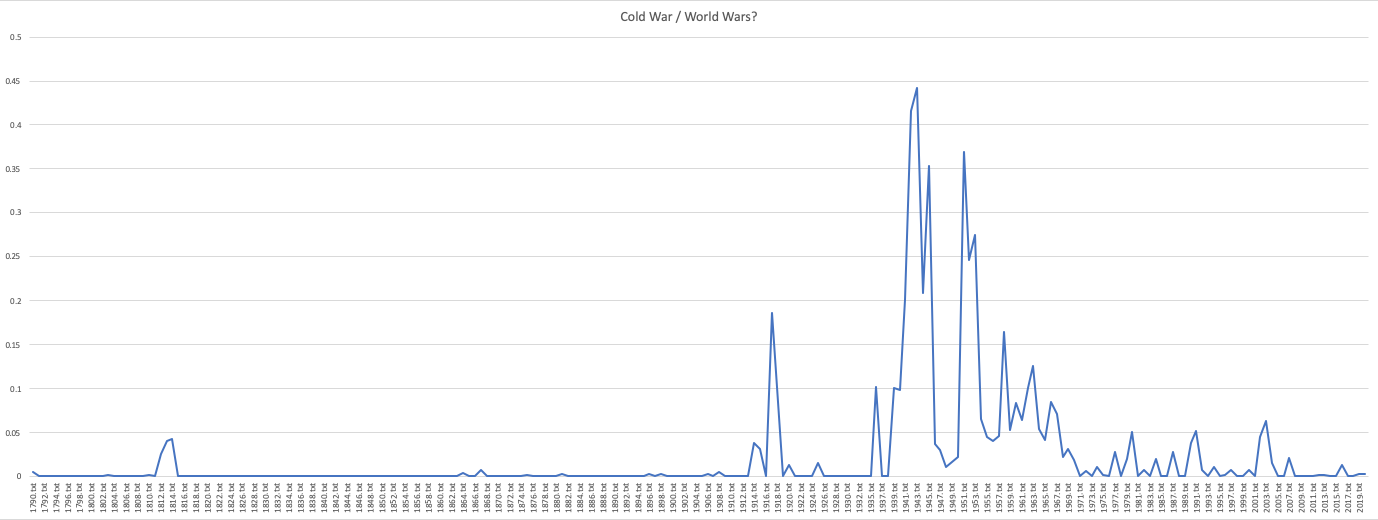 (Click for a larger view)
(Click for a larger view)Okay, so that’s not too surprising. Given that we thought that topic might be about 20th century wars, it makes sense that we see much more frequency for this topic in the 20th century.
Our model shows that this topic spikes a bit during the War of 1812, more in World War I, and much more during World War II and the Cold War. Given that we saw words like “soviet” and “communist,” it’s not surprising to see that this model applies most to the wars of the mid-20th century.
But what is this missing? We don’t see such large spikes during the Civil War or the wars of the Middle East during the late 20th and 21st century. Why? Well, let’s return to our keys:
war free nations world military peace production forces united communist men defense effort strength aggression fighting soviet attack europe peoples
Now that I have a bit more context, my eye goes straight to “Europe” here. Perhaps MALLET has really identified a “European wars” topic. In doing so, perhaps it’s indicating that the rhetoric in States of the Union surrounding the Civil War and wars in the Middle East was different in some significant ways than the rhetoric surrounding wars between the United States and European powers.
That may be worth investigating in more depth. If I ever wanted to write a book or article about presidential rhetoric about war, that would be a potentially interesting line of inquiry. So MALLET has helped me to generate a historical question: “How did U.S. presidential rhetoric about wars in Europe differ from rhetoric surrounding non-western wars?”
Step 6: Analyze your own keys and composition
A crucial thing to note about MALLET is that every time you use it on the same corpus, even with the same inputs in the terminal, you’ll generate different results. Your results will be different from mine, and from your classmates.
If you want to run this process a second time, you can simply enter this command again, which features a slight amendment to the output file names:
bin/mallet train-topics --input sotu.mallet --num-topics 20 --optimize-interval 20 --output-state sotu.gz --output-topic-keys sotu_keys_2.txt --output-doc-topics sotu_composition_2.txt
Try to find a topic that has some coherence, and graph it to show how it changed over time. Does it make sense given what you know about American history? What surprises you? Is there anything that doesn’t make sense at all? What kinds of historical questions does this raise for you? How would you answer them?
Step 7: Think about potential applications to other text corpuses
The SOTU is a convenient example because it’s annual and their texts are easily accessible on the internet. But most of you probably aren’t that interested in States of the Union or presidential rhetoric as a historical subject. What might you be interested in investigating using this tool?
